Overview
Packages
The DeepPhysX project is divided into several Python packages: a CORE package which is able to communicate with a SIMULATION package and an AI package. This way, the CORE has no dependencies neither to a SIMULATION framework nor an AI framework, and any of those frameworks can be compatible with DeepPhysX.
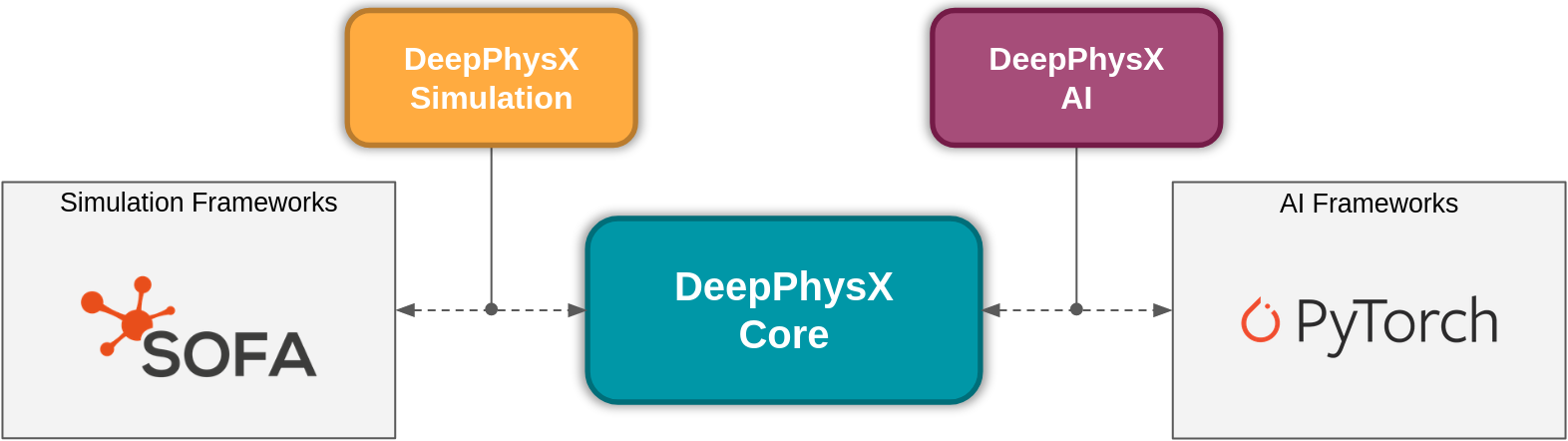
Package organization
Core
This package rules the data flow and the communication between the AI components and the simulation components. Data flow also involves the storage and loading of datasets and neural networks, the management of the visualization tool and the analysis of the training sessions. This package is named DeepPhysX.Core.
Dependencies
NumPy, Tensorboard, Vedo, SimulationSimpleDatabase
Simulation
A simulation package provides a DeepPhysX compatible API for a specific simulation framework. For DeepPhysX, each simulation package dedicated to a specific simulation framework (written in python or providing python bindings). Thus, each package will be named according to the framework with a common prefix, for instance DeepPhysX.Simulation.
Available simulation packages
DeepPhysX.Sofa designed for SOFA
AI
An AI package provides a DeepPhysX compatible API for a specific AI framework. In the same way, each learning package is dedicated to a specific AI Python framework. Thus, each package will be named according to the framework with the same common prefix, for instance DeepPhysX.AI.
Available learning packages
DeepPhysX.Torch designed for PyTorch
Architecture
This section describes both the links between the components of CORE package and the links to AI and SIMULATION packages.
Users might use one of the provided Pipelines for their data generation, their training session or their prediction session. These Pipelines trigger a loop which defines the number of samples to produce, the number of epochs to perform during a training session or the number of steps of prediction.
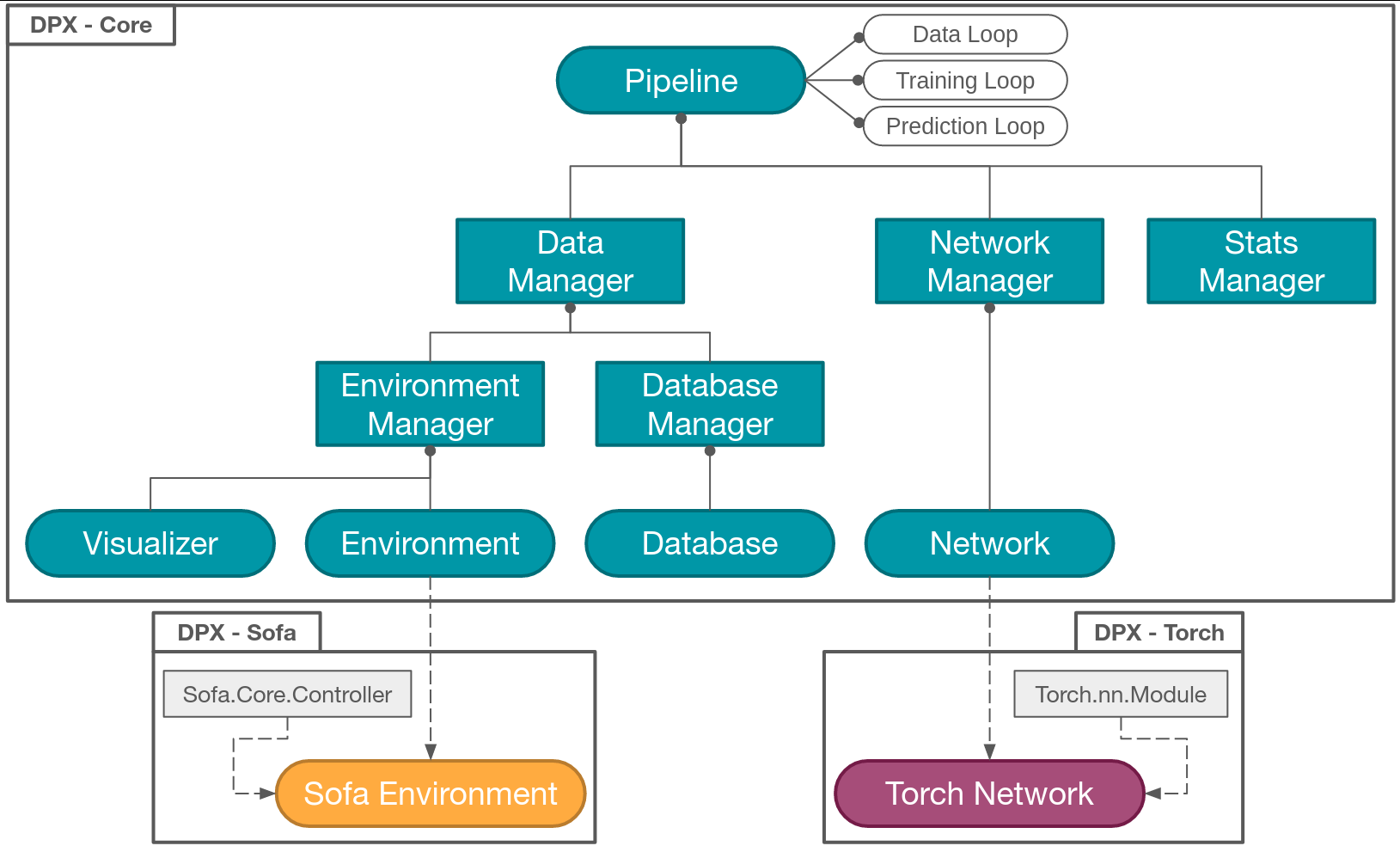
Components architecture
The Pipeline will involve several components (data producers and data consumers), but the Pipeline will always communicate with their Manager first. A main Manager will provide the Pipeline an intermediary with all the existing Managers:
DatabaseManagerIt will manage the Database component to create storage partitions, to fill these partitions with the synthetic training data produced by the Environment and to reload an existing Database for training or prediction sessions.
Note
If training and data generation are done simultaneously (by default for the training Pipeline), the Database can be built only during the first epoch and then reloaded for the remaining epochs.
EnvironmentManagerIt will manage the Environment (the numerical simulation) component to create it, to trigger steps of simulations, to produce synthetic training data, to provide predictions of the network if required, and to finally shutdown the Environment.
Note
This Manager can communicate directly with a single Environment or with a Server which shares information with several Environments in multiprocessing launched as Clients through a custom TCP-IP protocol (see dedicated section).
Note
The two above Managers are managed by the DataManager since both the Environment and the Database
components provide training data to the Network.
This DataManager is the one who decides if data should be requested from the Environment or from the
Database depending on the current state of the Pipeline and on the components configurations.
NetworkManagerIt will manage several objects to train or exploit your Network:
The Network to produce a prediction from an input, to save a set of parameters or to reload one.
The Optimizer to compute the loss value and to optimize the parameters of the Network. This component uses existing loss functions and optimizers in the chosen AI framework.
The DataTransformation to convert the type of training data sent from Environment to a compatible type for the AI framework you use and vice versa, to transform training data before a prediction, before the loss computation and before sending the prediction to the Environment.
Note
The above components are designed to be easily inherited and upgradable if the content of AI packages is not enough. Users are thus free to define their own Network architecture, to create a custom loss or optimizer to feed the Optimizer and to compute the required tensor transformations in the DataTransformation.
StatsManagerIt will manage the analysis of the evolution of a training session. These analytical data will be saved in an event log file interpreted by Tensorboard.
Note
Usual curves will be automatically provided in the board (such as the evolution of the loss value, the smoothed mean and the variance of this loss value per batch and per epoch), but other custom fields can be added and filled as well.
Warning
It is not possible to use the default Network and Environment provided in the CORE package, since they are not implemented at all. The reason is that you need to choose an AI and a SIMULATION Python framework to implement them. The aim of DeepPhysX additional packages is to provide a compatible implementation both for DeepPhysX and these frameworks.
- Example
If you choose PyTorch as your AI framework, you can use or implement a TorchNetwork which inherits from both the CORE Network and
Torch.nn.module(available in DeepPhysX.Torch).If you choose SOFA as your SIMULATION framework, you can implement a SofaEnvironment which inherits from both the CORE Environment and
Sofa.Core.Controller(available in DeepPhysX.Sofa).